Cover Story
Don't judge a book by its cover. Judge it by its linguistic
productivity instead!
You'll probably want to read this on desktop. If on mobile you can
read a less cool version of this previously published on my blog.
Thanks also to my friends at the blablablab for their advice and help.
Matisse is a team player
Two very influential artists, to be sure, but why was Matisse collaborating with ancient Kabbalists, and what exactly did the people want from Leonardo’s shadow?
Some Context...
In mid-June, Randall Munroe, the genius behind xkcd and the author of quite a few books, announced he was going on a book tour to promote his latest book: How To: Absurd Scientific Advice for Common Real-World Problems
As part of the announcement, he introduced an interesting challenge:
Write the best story using nothing but book covers.
The winner of the challenge would be rewarded by a visit from Munroe as part of the tour. Even though Ann Arbor was already in the itinerary, I couldn’t help but think about this challenge… and how I could use some of my linguistics knowledge to my advantage.
I decided I would try to hack this challenge by acquiring a dataset of book titles, and having a computer generate these stories for me.
I found a list of over 200,000 books listed on Amazon, and a couple of Jupyter notebooks and Python packages later, we were off to the races.
Grammar School
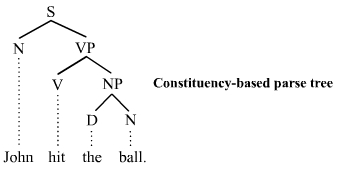
The key concept behind this project was something I learned in my introduction to linguistics class last fall: constituency trees. The basic idea is that each sentence can be represented as a combination of words and phrases (constituents).
For example, a sentence is, in its base form, a noun phrase and a verb phrase.
And a noun phrase might be a noun, with optional adjectives and determiners, and maybe a prepositional phrase...
...and because prepositional phrases can also have noun phrases, we can chain these together recursively. In fact, many linguists believe that all human language is recursive. See here and here for more background and some linguist turf wars.
And in this way, we can construct a very expressive and productive grammar for the English language. Productivity here means that, with even a limited vocabulary, we can form many distinct sentences and thoughts.
So the main idea was we would label each book title as a noun phrase, verb phrase, adjective phrase, etc. Then, we could use this grammar to compose sentences which may not make a ton of sense, but are at least grammatical.
I used benepar, which is a state of the art constituency parser that fits nicely into NLTK. I found that it provided decent results. One issue that I ran into was handling more granular details such as subject verb plurality alignment. In those cases, I wanted to know what the noun was in the noun phrase, etc.
For this, I used a different grammar model: dependency grammar. In dependency grammars, instead constituents, each word is dependent on exactly one other word in the sentence.
I use the root of each dependency tree as the “active noun” or “active verb” in the phrase, and their parts of speech include markers for plurality, properness, verb tense, etc.
There were just a couple of other edge cases I handled, which is why the phrase tags I end up using do not line up entirely with the Penn Treebank tagset.

Try it out!
Select a phrase type from the dropdown to insert it into your sentence. Double click to shuffle the title. Right click to delete.
Add a new